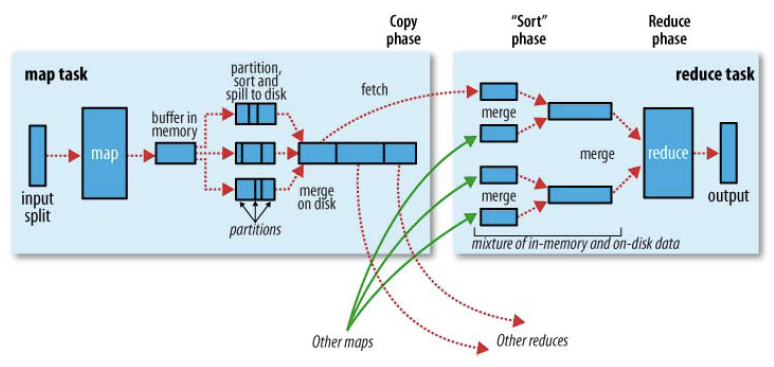
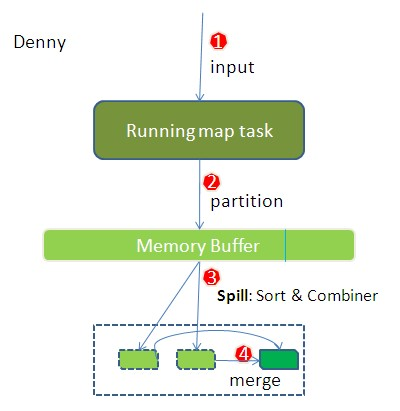
- 提交的任务,经过map后(形成key/value对,还包括partition,partition表示为map片段分配对应的reducer)存入内存缓冲区,并做了一些预排序。
- 当缓存大小超过限制(默认:分配的内存的80%),开始进行spill
- spill会进行sort,会在partitions之间进行排序以及对相同的partition里面的元素进行排序。
- spill时,默认将元素组成<key, value-list>的形式(简单的将values放到一起),如果定义了conbiner的话,会对values进行操作,如何在word count中,会将value相加。
- map阶段结束时,会将所有的spills, merge为一个,并通知jobtracker。
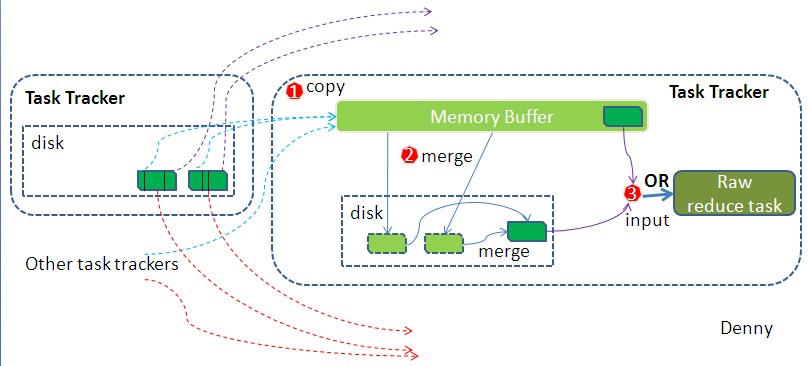
- reducer通过联系jobstracker,知道某个map的任务完成了,进而将map结果复制过来。相同的key的map,会传到同一个reducer。
- 将不同的map结果,进行merge,如果有conbiner也会执行。
- 将合并后的结果,作为输入传给reducer。
参考
http://zheming.wang/blog/2015/05/19/3AFF5BE8-593C-4F76-A72A-6A40FB140D4D/